This section explains in greater deatail the internal workings of the SlidingBuffer to assist with its extension, and to demonstrate its features and limitations.
There are many applications which need to refer to the recent history of an input data stream. Examples of such might include image identification and tracking, audio feature identification and, the reason for which this template class was developed, identification and localisation of the onset of musical notes in an audio stream. Processing proceeds in the forward direction, starting at the beginning of the stream, but occasionally makes reference to the frames in the recent past. It is very convenient to be able to refer to recent data frames simply by their position in the stream, but reading them all into memory ahead of time may be impractical if the stream is unbounded or real-time operation is required. The idea of the SlidingBuffer is to cache recent frames from the input stream, permitting a an application to refer to them directly by there index using the [] operator. Thus the stream appears to be a single long array, so long as references are not made too far into the past.
Suppose a SlidingBuffer has been instantiated with a maximum of four segments each containing size integer entities. An additional instance of class IntGenerator has been provided, myInts, derived from slidingbuffer:SegmentProducer, to fill such segments.
The act of accessing the 0th entity in the sliding buffer will cause the SegmentProducer's generate() method to be invoked, and to fill one segment with data. The calling program may now access indices up to [size-1] without further invocation of generate().
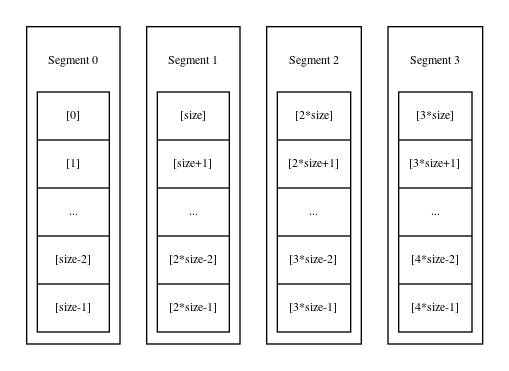
As the index into the buffer increases above [3*size] (but strictly less than [4*size]), the data held in the SlidingBuffer will be represented as in the following diagram. At this stage, all of the integers generated so far, from sb[0] to sb[4*size-1] will be accessible.
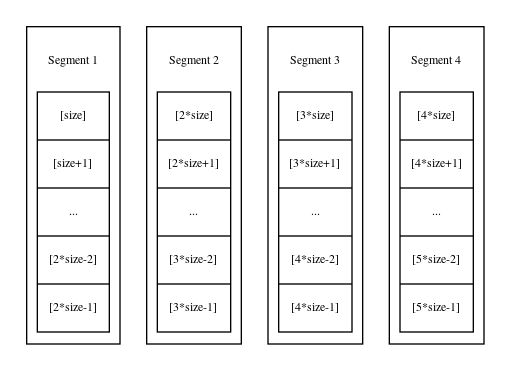
After index [4*size] has been accessed, the 4th call to generate() produces another buffer segment. However, since the maximum size of the SlidingBuffer was declared to be 4 Segments when it was constructed, the 0th segment along with all of its contained entities are destroyed.
The storage disposition is now as shown in the following diagram; integers with indices of at least [size] but less than [5*size] can be accessed.
SlidingBuffers do bounds checking, throwing an instance of an object derived from slidingbuffer::SlidingBufferException. These are:
- slidingbuffer::NegativeIndexException when an attempt is made to access an entity at index less than 0;
- slidingbuffer::IndexOutOfRangeException when an attempt is made to access an entity which is at an index greater than the maximum currently stored, and the Producer is unable to supply any further data (perhaps it has been supplying data from a file and reached the end of the file);
- slidingbuffer::ExpiredIndexException when the SlidingBuffer has already discarded the entity requested in order to make space for furter entities to be generated.
Should the index skip forward to the extent that several segments are never used, the SlidingBuffer will nonetheless call generate() to read intervening samples before discarding them. This enables a Producer which is in some respect maintains the current input position and relies upon it to return correct data to perform correctly even when the input position jumps forward abruptly.
A minimal example exercising these features is shown in the C++ example below.
In normal usage, because there is a noticable fetch overhead in returning a single entity, so one would expect them to be larger than a simple type. In the case that the entities are essentially simple, or at least one-dimensional types, appropriate templates may be used to provide the desired functionalities. Two and higher dimensions require additional effort to redefine the operator[] access method depending on their semantics.
